The first project is a Python application for linear optimization with several hundred lines of code, the second is a C# heuristic based on a beam search with about two thousand lines, the third is a SvelteKit application for managing wholesalers, products, and offers with around fifty thousand lines of code, and the fourth is a React/Refine application with a Directus backend.
ChatGPT 5, Claude Sonnet 4.5, Claude Opus 4.1, and Gemini 3.0 Pro were used as AI systems.
Large Language Models and the Nature of Probabilistic Generation
Modern AI assistants are based on Large Language Models (LLMs), which are trained to predict the next token based on statistical probabilities. Instead of following explicit logical proofs, they perform a probabilistic continuation: each generated token is selected according to conditional probability distributions learned from the training data.
This mechanism allows for remarkable eloquence in natural language as well as in source code, but it comes with structural limitations. The model’s “reasoning” is local in nature and is guided more by token proximity and statistical association than by deterministic logic, type systems, or formal proofs.
For software engineering, this means that correctness, consistency, and architectural conformity cannot be proven within the model’s internal process. LLMs reproduce syntax and stylistic patterns but lack the ability to verify whether generated code compiles, executes correctly, or coherently integrates into a larger system. These probabilistic foundations define the systemic limitations we examine below.
Sign Up for Our Newsletter
Stay Tuned & Learn more about VibeKode:
Operational Model of AI Coding Assistants
An assistant operates within a limited conversation session, exchanging messages and code fragments with the user. Each system maintains a context window—a token-based memory limit that defines how much information can be processed simultaneously. When new material exceeds this limit, earlier content is either discarded or summarized, reducing effective memory.
Two operational modes can be distinguished. In a complete-bundle configuration, the entire project is provided upfront, enabling a consistent internal model as long as it fits within the context limit. In contrast, incremental or vibe-coding workflows build understanding step by step, as the developer exposes parts of the codebase. The assistant never holds the entire system in focus at once, resulting in a partial and evolving representation. Retrieval mechanisms complement this process by loading relevant material on demand through semantic or symbolic search.
Context, Retrieval, and Embeddings
Multi-layered Context in IDE-integrated Assistants
In practice, IDE-integrated assistants assemble multiple layers of context for each generation step:
- Local editing state: The currently open files (“tabs”), including the code immediately around the cursor and recent changes.
- Indexed project context: Information from the IDE’s internal code index—such as symbol definitions, imports, and type relations—from other files in the project. This indexing often interacts with the IDE’s Language Server Protocol (LSP).
- Embedding-based retrieval: Semantically related fragments from the entire codebase, dynamically retrieved when relevant.
- The “core” LLM: The model containing the “static” (pre-trained) programming knowledge, e.g., Claude Sonnet, ChatGPT, Gemini Flash/Pro, DeepSeek, etc. This is the “large” entity pre-trained with programming knowledge. Layers 1–3 are combined through a prompt-composition process, where heuristics determine which excerpts—function signatures, class definitions, or short code blocks—fit into the available context window for the next model call.
Sidebar: “Embeddings”
Embeddings are vector representations of text or code that capture semantic similarity. They enable similarity-based retrieval instead of “full-text search.” Based on an embedding of the current query, the system identifies nearby vectors in a precomputed index and retrieves the corresponding fragments. The advantage is clear: instead of relying on similar text strings, the system “understands,” for example, that MyUserClass and the Authentication algorithm are somewhat related.
However, embeddings represent only approximate meaning, rather than precise structure. They do not preserve control flow, dependency hierarchies, or type safety. The retrieved fragments are therefore thematically relevant but not guaranteed to be logically consistent with the overall system.
Live – Code – Repeat
All tested Vibe-Coding assistants exhibit, to varying degrees, a recurring read–search–edit cycle: the assistant inspects selected files, generates changes, searches for related elements, retrieves additional fragments, and repeats the process. A typical sequence looks like this:
read(File A) → read(File B) → search(“Symbol”)
→ update(changes) → read(File C) → update …
The differences between tools lie in efficiency details: some tools repeatedly read files “fresh,” while others continuously update the indexed project context via a file watcher.
Regardless of the method, the context sent to layer 4—the “core” LLM—is constantly rebuilt. This context turnover causes relevant project parts to be repeatedly re-extracted and inserted into the limited window, displacing earlier details.
Building Context Smarter – Retrieval-Augmented Generation (RAG)
Some tools reconstruct the entire context based on the indexing mechanisms described above and send it to the LLM. This is akin to a human sending all the information again with every prompt, similar to the “Full Bundle Configuration” mentioned earlier.
Other tools send only the parts they “believe” are relevant to the context. This process – known as Retrieval-Augmented Generation (RAG) – extends the assistant’s effective reach beyond its immediate conversational memory [1].
Sign Up for Our Newsletter
Stay Tuned & Learn more about VibeKode:
The “Full Load” or Prompt-Caching: Prerequisite for Meaningful RAG
Even though a coding assistant using RAG does not need to send the full context to the LLM every time, a special prerequisite is required: prompt caching. If the LLM API were purely stateless, there would be no choice but to always send the entire context. Therefore, most LLM API providers offer prompt caching: the LLM server retains the context for a certain period. This is similar to a human gradually feeding information to the model in a prompt session.
For example, in a Full Bundle Configuration, you upload your entire codebase. If you later rename a method locally from A to B, you tell the LLM, “I renamed method A to B.” The model updates its internal state and will subsequently recognize method B within your session. Similarly, in prompt caching, the coding assistant sends extracted parts to the LLM, which can apply corresponding updates.
Caution: Depending on the model, larger parts of the cache may be invalidated because the stored context is essentially a “heap of text.” Unlike an IDE’s language server, the LLM has no abstract or concrete syntax tree.
Prompt caching is the economic enabler for Vibe-Coding. Without server-side retention of already processed code blocks, latency during each refactoring step would be unbearable, as the model would have to “re-read” the entire project each time. However, caching solves computational load, not selective perception: the AI still only sees what the RAG system places into the window.
Local vs. Cloud-based Semantic Embeddings
Many coding assistants are IDE plugins that primarily read and write files while delegating the rest to a cloud system. This raises the question: where does “Layer 3,” semantic indexing, and search occur? In other words, how does the system know that the code in MyUserClass belongs to the Authentication workflow?
Most tools (Cursor, Claude Code, etc.) offload this semantic search largely to a cloud system running a vector database and an embedding LLM. This is not yet Layer 4—the actual LLM containing programming knowledge. Once the cloud-based semantic search finds the relevant snippets, the Vibe-Coder sends them to the core LLM.
Flow:
Coding Assistant, Your Code Project (Layer 1)
→ Local Index (Layer 2)
→ Semantic Index (Layer 3)
→ Return retrieved snippets to Coding Assistant
→ Send to Core LLM (Layer 4)
→ Coding Assistant optionally applies local code changes.
Other tools (e.g., Roo Code) allow a more flexible setup: they use a locally installed vector database (e.g., Qdrant) and a local embedding model (e.g., Ollama – nomic-embed-text). The developer machine is typically sufficient to run such an embedding model. Unlike the “core” LLM, which may require several hundred GB of RAM (roughly 50–200 MB per thousand tokens, depending on the model).
From Passive Searching to Active Action: LLM Agents – TOOL USE
Modern assistants go beyond passively feeding context. Using Tool Use, the core LLM (Layer 4) independently decides which search tool it currently needs. A local plugin could hardly make this decision: while a rigid algorithm can only guess, the LLM situationally determines whether a vague idea requires the “compass” (semantic search) or precise refactoring requires the “magnifying glass” (grep). Only through this agentic behavior can the AI iteratively operate like a human developer: first surveying architecture, then targeting exact code symbols.
Flow:
Coding Assistant, Your Code Project (Layer 1)
→ Local Index (Layer 2)
→ Semantic Index (Layer 3)
→ Return found snippets to Coding Assistant
→ Send to Core LLM (Layer 4)
→ Optional TOOL USE (“grep ‘MyUserClass’”)
→ Back to Layer 4
→ Coding Assistant optionally applies local code changes.
Systemic Outcome
After this dive into the workings of the four layers of coding assistants, one might think: “Everything is fine! Modern tools with semantic search and agentic TOOL USE are highly efficient.” Yes, but:
Despite multiple layers, assistants remain limited by the finite context window. Prompt composition relies on heuristic selection, embeddings and tool use provide only partial information, and no complete project state is persistently stored. The consequences are:
- Partial Knowledge: Cross-file relationships and global invariants rarely coexist in memory.
- Repeated Retrieval: Relevant code often must be fetched multiple times.
- Incomplete Architectural Model: Similarity search or selective tool use cannot reconstruct full structural dependencies.
- Probabilistic Reasoning: Generation remains statistical, allowing plausibly looking but incorrect code.
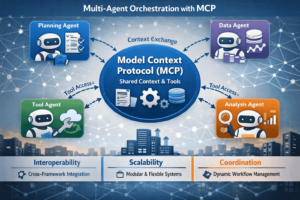
Advanced Context Solutions: The Model Context Protocol (MCP)
To overcome the limitations of generic on-the-fly retrieval, platform providers are introducing more sophisticated, protocol-based solutions. A prominent example is the Model Context Protocol (MCP) [2]. MCP acts as a dedicated interface, providing the LLM with a centralized, curated knowledge source. It allows organizations to index their entire private codebase, internal documentation, and coding conventions, delivering highly relevant context for every request.
This protocol-driven approach offers advantages over standard retrieval:
- Higher precision: Provides exact API definitions rather than just semantically similar snippets
- Reduced hallucinations: Grounding in a trusted knowledge base lowers the risk of referencing non-existent code
- Better consistency: Team-specific conventions are established as a primary part of the context
Nonetheless, MCP does not change the probabilistic nature of the LLM. The generation step remains a statistical prediction and still requires the deterministic validation described in “The Vision.”
Sign Up for Our Newsletter
Stay Tuned & Learn more about VibeKode:
Practical Risks and Workflow Implications
The combination of probabilistic inference and limited context leads to noticeable inefficiencies in the developer workflow.
Consequences of Probabilistic Generation
The mechanism becomes particularly apparent with incomplete project data: every addition is a continuation of observed tokens guided by statistical similarity. Even when naming conventions and syntax are correctly reproduced, correctness depends on relationships outside the visible window.
Typical symptoms include:
- Code that appears coherent but fails to compile
- References to undefined variables or functions
- Violations of layer separation (e.g., backend logic in UI components)
Dev Workflow: Capacity and Planning Uncertainty
Many assistants do not expose their remaining context capacity. Developers often only notice when large edits abruptly fail, indicating that the memory limit has been reached.
When this limit is exceeded, agents must “compact” the conversation—creating an internal summary and discarding details. Some Vibe Coders do this silently in the background. The system appears continuous but, provocatively, resembles a “Memento effect”: it loses short-term memory but still behaves as if it remembers. Reconstruction via retrieval is only an approximation, subtly altering the internal model of the project with each cycle.
Added to this is usage-based pricing. Team productivity becomes dependent on token quotas and vendor limits rather than technical skill.
Efficiency and Cognitive Overhead
While routine tasks are offloaded, new coordination costs emerge. Developers must repeat rules and verify code that looks correct but fails tests. Humans effectively become the assistant’s external memory controller. Time spent on clarifications and corrections can reduce nominal efficiency gains.
Integration Deficits
Software development is iterative and stateful (builds, tests, deployments). AI assistants, however, operate on static context snapshots with weak coupling to build or test pipelines, making refactorings and architectural evolution error-prone.
Security Aspects
Probabilistic generation can introduce subtle security vulnerabilities (e.g., unparameterized queries, missing validation). Studies indicate significant portions of AI-generated code contain security flaws (Veracode 2024: 45%), and developers assisted by AI tend to produce less secure code [5], [6]. AI-generated code must therefore be treated as untrusted input and verified using static analysis tools (CodeQL, SonarQube).
Cognitive Offloading
A critical behavioral aspect is cognitive offloading—the tendency to delegate mental effort to the system. While an effective developer traditionally strives to understand the system (OODA loop: Observe, Orient, Decide, Act), AI interrupts this learning cycle.
Instead of analyzing errors, developers delegate problem-solving via “Fix this” prompts back to the agent. This creates a vicious cycle: because the code is never fully understood, dependency on the assistant grows. Procedural memory and internal system understanding remain shallow, and self-efficacy can erode: confidence in one’s own skills decreases while dependence on the external “expert voice” of the AI increases [9].
Strategic Use and Safe Boundaries
AI assistants currently excel at:
- Generating boilerplate and scaffolding
- Prototyping
- Explaining and translating unfamiliar code
- Exploring new libraries
- Developing small, self-contained modules
However, their usefulness rapidly diminishes for mature codebases with specific conventions, cross-component refactorings, or security-critical tasks. Timely disengagement from AI dialogue during escalating correction cycles is essential.
The Vision: Paths to Deterministic and Hybrid Systems
Overcoming the Context Bottleneck
The quadratic cost increase with larger context windows is a major scaling obstacle. New architectures such as xLSTM (Prof. Sepp Hochreiter [10]) or other long-context models promise to efficiently process longer sequences, reducing the need for complex retrieval workarounds.
Structural and Logical Validation
A reliable architecture should rely on two deterministic layers:
- Structural validation: Leveraging modern IDE language-server architecture and maintaining abstract/concrete syntax trees (AST/CST). An assistant integrated with this model cannot hallucinate non-existent entities.
- Logical validation: Applying automated reasoning (AR) to the AST. Architectural rules (e.g., “Service may not call DB directly”) act as axioms against which changes are verified.
The Hybrid Loop
A hybrid system integrates probabilistic generation into a generate-validate loop:
- LLM generates a suggestion
- Structural validator checks syntax against the AST
- Logical validator tests compliance with architectural rules
Only validated code is presented to the developer. Current challenges for this approach include additional latency, handling incomplete/invalid code during writing, and the effort required to formalize architectural rules.
Sign Up for Our Newsletter
Stay Tuned & Learn more about VibeKode:
Conclusion
AI coding assistants continue to make significant progress, but they remain limited in predictability due to their finite context and probabilistic nature. Advanced solutions like the Model Context Protocol improve precision but do not alter the statistical core of generation.
For exploration and routine tasks, these tools are invaluable. For sustainable development of complex, security-critical systems, however, human oversight – supported by deterministic analysis tools – remains the indispensable foundation of software engineering.
Further Readings
[1] Lewis, P., et al. (2020). “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” Advances in Neural Information Processing Systems 33.
[2] Microsoft. (n.d.). “Copilot: MCP Servers.” Visual Studio Code Docs. Retrieved from https://code.visualstudio.com/docs/copilot/customization/mcp-servers
[3] Microsoft. (2016). “Language Server Protocol Specification.” Microsoft Docs.
[4] OWASP Foundation. (2023). “OWASP Top 10 for Large Language Model Applications.”
[5] Perry, N., et al. (2022). “Do Users Write More Insecure Code with AI Assistants?” arXiv preprint arXiv:2211.03622. Stanford University.
[6] Veracode. (2024). “State of Software Security: AI Edition 2024.” Veracode Report.
[7] Kirschner, P. A., Sweller, J., & Clark, R. E. (2006). “Why Minimal Guidance During Instruction Does Not Work: An Analysis of the Failure of Constructivist, Discovery, Problem-Based, Experiential, and Inquiry-Based Teaching.” Educational Psychologist, 41(2), 75–86.
[8] Clark, R. C., Nguyen, F., & Sweller, J. (2005). Efficiency in Learning: Evidence-Based Guidelines to Manage Cognitive Load. San Francisco: Pfeiffer.
[9] Bandura, A. (1997). Self-Efficacy: The Exercise of Control. New York: W. H. Freeman.
[10] Orvieto, A., De Mambro, V., Pezeshki, M., Lucic, M., & Hochreiter, S. (2024). xLSTM: Extended Long Short-Term Memory. arXiv preprint arXiv:2405.04517.
[11] Schmidhuber, J., & Hochreiter, S. (1997). “Long Short-Term Memory.” Neural Computation, 9(8), 1735–1780.
[12] Peng, B., et al. (2023). RWKV: Reinventing RNNs for the Transformer Era. arXiv preprint arXiv:2305.13048.
[13] Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” Advances in Neural Information Processing Systems 35.
🔍 Frequently Asked Questions (FAQ)
1. What is “vibe coding” in the context of AI-assisted development?
In this article, “vibe coding” refers to incremental, assistant-driven workflows where the developer exposes parts of a codebase step by step. The assistant builds only a partial, evolving understanding because it never holds the entire system in focus at once.
2. Which AI coding assistants and LLMs were evaluated?
The article examines real-world usage of tools including Cursor, Aider, Roo Code, JetBrains Pro AI Agent (Rider/WebStorm), GitHub Copilot (VS Code), and Claude Code. It also names ChatGPT 5, Claude Sonnet 4.5, Claude Opus 4.1, and Gemini 3.0 Pro as the LLMs used.
3. What kinds of software projects were used to test these assistants?
Four projects are described: a Python linear-optimization app (hundreds of LOC), a C# heuristic using beam search (~2,000 LOC), a large SvelteKit app (~50,000 LOC), and a React/Refine app with a Directus backend. The variety is used to show practical limitations across different sizes and stacks.
4. Why do LLM-based coding assistants have structural limits on correctness?
The article explains that LLMs generate output probabilistically by predicting the next token, rather than following deterministic logic or proofs. As a result, they can mimic syntax and style but cannot internally prove compilation, runtime correctness, or architectural conformity.
5. What is Retrieval-Augmented Generation (RAG) in Vibe Coding?
RAG enriches AI-generated outputs by retrieving up-to-date project or API data. This compensates for the model’s static training data and improves alignment with current implementation requirements.
6. What is a “context window,” and why does it matter in IDE assistants?
A context window is the token-based limit on how much information the assistant can consider at once during generation. When the limit is exceeded, earlier content is discarded or summarized, which can remove important details needed for consistent changes across a project.